XPath的使用
2025-09-10 10:09AM
方法1:在浏览器开发者工具中直接测试
1. 使用Chrome 或 Firefox浏览器打开一个网页
2. 点击 F12 打开开发者工具
3. 切换到 Elements(查看器/元素)面板
4. 点击 ctrl + f 在底部搜索框中输入你的 XPath 表达式
5. 如果表达式正确,它就会高亮显示匹配到的元素,并告诉你找到了几个。
例如:
打开这个链接:https://www.runoob.com/try/xml/books.xml
在搜索框中输入 /bookstore/book/title 选取所有 title 节点
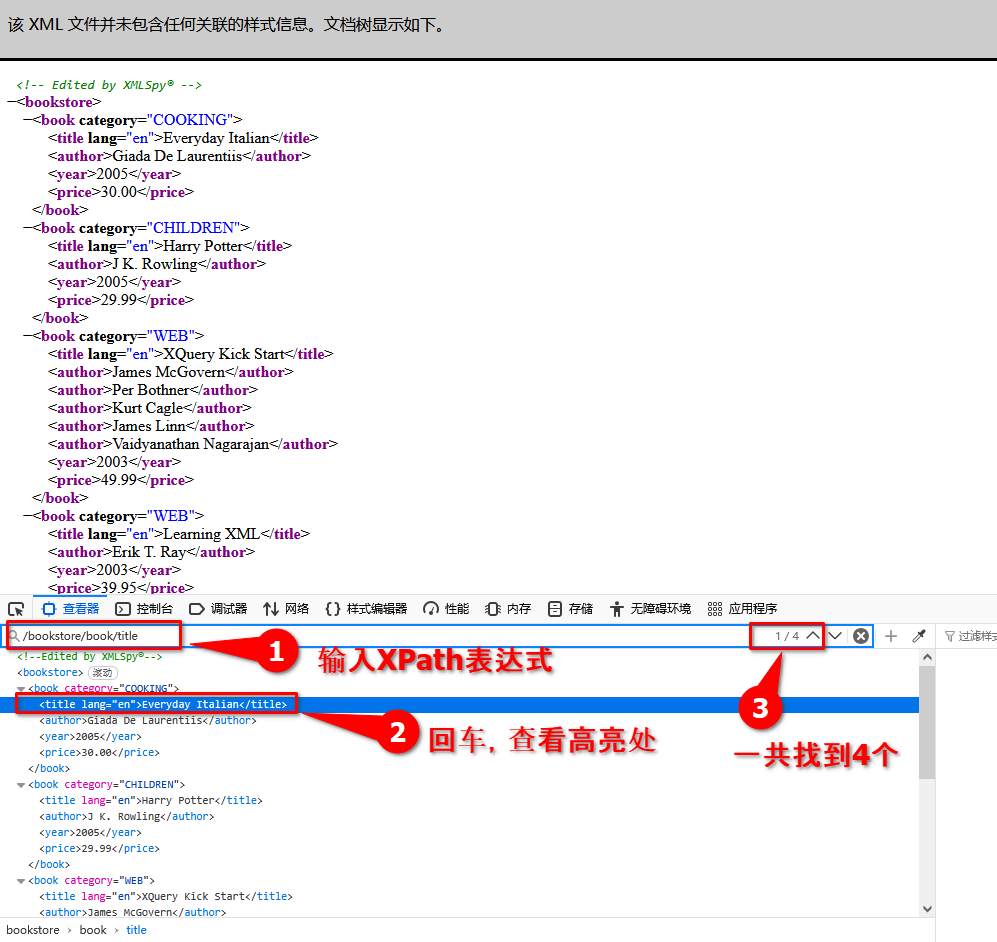
4个分别是:
Everyday Italian
Harry Potter
XQuery Kick Start
Learning XML
方法2:在编程中使用
XPath本身不是编程语言,它需要被其他语言调用,最常用于:
Python(使用 lxml 或 parsel 库):
from lxml import html source = """ <html><body><div><a href=‘https://www.example.com’>链接</a></div></body></html> """ selector = html.fromstring(source) # 使用XPath提取链接地址 link_url = selector.xpath(‘//a/@href’)[0] print(link_url) # 输出: https://www.example.com
总结:
理解结构:学习XPath前,最好先对HTML的树状DOM结构有个基本了解。
多用浏览器练习:F12 -> Ctrl+F 是最佳练习场。看到页面上的任何元素,都试着用XPath去定位它。
从简单到复杂:先掌握 //, /, @, [] 这几个最核心的符号,然后再去学习函数如 contains(), text(), starts-with() 等。
避免过于脆弱的XPath:尽量避免使用绝对路径(如/html/body/div[2]/div[5]/div[1]/div/span),因为页面结构稍一变化,路径就失效了。尽量使用属性和相对路径来构造更健壮的XPath(如 //div[@class=“title”]/span)。
登录
请登录后再发表评论。
评论列表:
目前还没有人发表评论